W poprzednim wpisie opisywałem cztery metody estymacji wytwarzania oprogramowania, które są stosowane w praktyce – ale ich rezultaty są często niezadawalające. Dzisiaj poszukamy metody, która działa lepiej. Ale najpierw czeka nas mała wycieczka w stronę epistemologii…
Racjonalizm i empiryzm
Wyobraźmy sobie taką sytuację: musimy oszacować, ile czasu zajmie nam przejechanie samochodem z Gdańska do Warszawy. Jak to zrobić?Możemy tutaj użyć dwóch różnych sposobów.
Pierwszy sposób polega na znalezieniu idei lub modelu, który pomoże nam w zrozumieniu i rozwiązaniu tego problemu. Możemy przypomnieć sobie z fizyki wzór t = S / v, obliczyć odległość między Gdańskiem a Warszawą, oszacować prędkość naszego samochodu – i mamy szacunek czasu przejazdu. Jeżeli między Gdańskiem a Warszawą jest 360 km, jeżeli będziemy się poruszać ze średnią prędkością 90 km/h, to cała droga powinna nam zająć 4 godziny.
Drugi sposób polega na znalezieniu doświadczeń, które będziemy mogli wykorzystać do szacowania. Czy jechaliśmy kiedyś samochodem z Gdańska do Warszawy i ile czasu nam to zajęło? A może jechaliśmy do jakiegoś innego miasta, które było w podobnej odległości? A może jechaliśmy do miasta, które było bliżej albo dalej i możemy użyć jakiegoś przeskalowania? A może ktoś z naszych znajomych jechał do Warszawy i może nam powiedzieć, ile czasu to trwało?
Epistemologia, czyli nauka o poznaniu, nazywa pierwszy sposób racjonalizmem albo aprioryzmem, a drugi – empiryzmem albo aposterioryzmem.
W życiu codziennym używamy obu sposobów naprzemiennie, w zasadzie nie zastanawiając się nad tym, którego sposobu używamy. Często też łączymy ze sobą różne modele myślowe oraz wiedzę wynikającą ze wcześniejszych doświadczeń.
Ale najciekawsze jest to, że im nasze środowisko jest bardziej złożone, tym lepiej sprawdzają się w nim metody empiryczne. Problem estymacji czasu przejazdu samochodem osobowym z Gdańska do Warszawy jest na tyle prosty, że można z powodzeniem stosować obie metody. Ale co będzie, jeżeli zwiększymy złożoność naszego problemu i będziemy chcieli oszacować, ile czasu zajmie nam przejechanie autostopem z Gdańska do Barcelony? W tym przypadku mamy tyle zmiennych i niewiadomych, że może się okazać, że nie znajdziemy wzoru do estymacji czasu przejazdu. Ale znam ludzi, którzy mają doświadczenie w jeżdżeniu stopem po Europie i na podstawie tych doświadczeń mogą powiedzieć, ile czasu może zająć taki przejazd.
Jaka pogoda będzie jutro?
W wytwarzaniu oprogramowania najczęściej jesteśmy w domenie złożonej. Napotykamy na niespodziewane przeszkody. Mamy więcej niewiadomych niż wiadomych. Mamy dużo powiązań i zależności. Czy mamy jakieś empiryczne metody szacowania? Czy mamy metody szacowania oparte na naszym doświadczeniu?
Okazuje się, że mamy.
Metodą empiryczną jest podejście „yesterday’s weather” czyli metoda wczorajszej pogody. Załóżmy, że mamy zespół wytwarzający oprogramowanie. Załóżmy, że zespół ten potrafi dekomponować swoją pracę na małe zadania. Jak mamy małe zadania, to wiemy kiedy takie małe zadanie się zaczyna i kiedy się skończyło. Załóżmy, że na jakiejś tablicy ten zespół zapisuje sobie, ile czasu trwało każde zadanie.
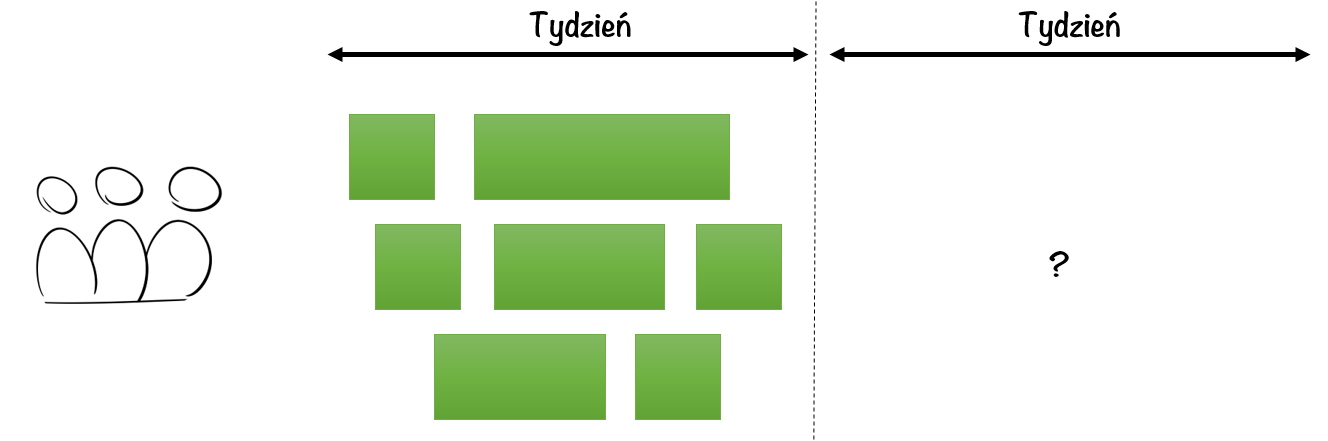
Jeżeli w ciągu jakiegoś okresu czasu – na przykład w ciągu tygodnia – zespół skończył 7 zadań, to możemy z pewnym prawdopodobieństwem założyć, że następnym tygodniu zespół też skończy 7 zadań.
Oczywiście w praktyce mamy do czynienia z zadaniami różnej wielkości i trudności – dlatego albo stosujemy jakieś miary wielkości tych zadań (w świecie zwinnym często nazywamy je Story Pointami), albo stosujemy podejście #noestimate polegające na dekompozycji zadań do momentu, aż będą miały podobną wielkość.
A skąd taka nazwa metody? Okazuje się, że jeżeli chcemy przewidzieć jaka pogoda będzie jutro, to bardzo proste założenie „jutro będzie taka sama pogoda, jak była dzisiaj” daje nam całkiem niezłą przewidywalność. A tego, jaka pogoda była dzisiaj, doświadczyliśmy empirycznie, prawda?
Dlaczego metody empiryczne?
Dlaczego właściwie zawracamy sobie głowę tym całym empiryzmem? Dlatego, że w świecie złożonym nasze modele myślenia często wiodą nas na manowce. Zapominamy o pewnych czynnikach. Bazujemy na założeniach, które nie są prawdziwe. Popełniamy błędy poznawcze – a tych jest naprawdę dużo.
Dopiero obserwacja rzeczywistości pokazuje nam, jak jest naprawdę.
Przykład pierwszy, rowerowy. Musimy oszacować czas podróży rowerem z Gdańska do Kościerzyny. Trasa liczy 60 km. Podstawowe pytanie brzmi: z jaką prędkością będę poruszał się na rowerze? Jak jadąc ścieżką rowerową nad morzem, to spokojnie wyciągam 25 km/h, więc szacuję że będę jechał trochę wolniej, powiedzmy 20 km/h. Czyli 3 godziny i melduję się na rynku w Kościerzynie, gdzie napiję się niefiltrowanego i niepasteryzowanego piwa ze Starego Browaru. Brzmi jak plan!
A rzeczywistość? Podczas drogi okazuje się, że do Kościerzyny jest mocno pod górę (podjazd pod Wieżycę, fuj!), co jakiś czas trzeba robić przerwy na jedzenie, zdecydowaliśmy się zjechać z głównej drogi i jechać lasami, bo na głównej drodze było zbyt dużo samochodów, a tak w ogóle to jeszcze jedziemy pod wiatr. Średnia prędkość jest grubo poniżej 20 km/h, przejazd się wydłuża, a wizja zimnego piwa się oddala…
Przykład drugi, informatyczny. Pracowałem kiedyś z zespołem, który używał frameworku Scrum. Product Owner tego zespołu miał założenie, że zespół będzie miał prędkość 100 Story Points – czyli że w każdym sprincie będzie dostarczał zadania, których wycena będzie wynosiła 100 SP. Na tym założeniu Product Owner opierał daty dostarczenia, które pokazywał swoim interesariuszom.
Tymczasem rzeczywista prędkość zespołu była dużo mniejsza – dane historyczne za kilka sprintów pokazywały średnią prędkość gdzieś w granicach 70.
Jak bardzo przestrzelone były estymacje prezentowane przez Product Ownera?
Samooszukiwanie
Zostając jeszcze na moment przy tych dwóch przykładach – jeżeli jedziemy rowerem do Kościerzyny i podczas pierwszych dwóch godzin przejechaliśmy 30 km, to wiemy że nie będziemy na miejscu w ciągu trzech godzin. Nie pokonamy w ciągu jednej godziny kolejnych 30 km. Nie ma takiej opcji. Jeżeli do tej pory wiało nam w twarz, to będzie wiało nam nadal…
W projektach IT bardzo często bywa inaczej. Ktoś zakłada, że prędkość zespołu wynosi 100 SP. Widać, że to nie wychodzi. Widać, że średnia prędkość zespołu wynosi dużo mniej, a do tego jeszcze mocno się waha:
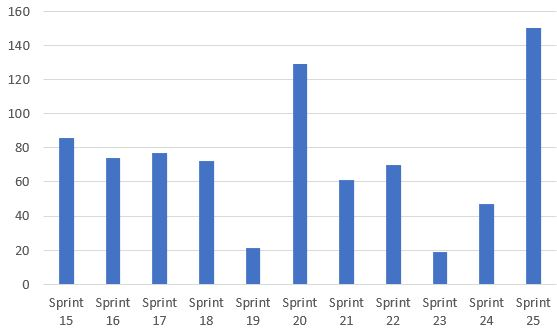
Ale bardzo często pomimo danych empirycznych, które pokazują że poruszamy się wolniej niż pierwotne założenia, wciąż zakładamy że w przyszłości będzie lepiej! „Tutaj dostarczyliśmy mało, bo był problem z integracją, tutaj Damian był chory, ale rozwiązaliśmy już te problemy i w przyszłości one nie wystąpią”.
Być może te właśnie problemy już nie wystąpią. A jakie jest prawdopodobieństwo, że wydarzą się inne problemy?
Tak naprawdę to jest bardzo proste!
Załóżmy, że mamy zespół IT, który:
- jest stabilny
- ma listę rzeczy do zrobienia (jeżeli pracujemy w Scrumie, to nazywamy tę listę Backlogiem Produktu)
- ma historyczne dane o tym, ile zadań / ile punktów jest w stanie dostarczyć w ciągu jakiejś jednostki czasu – w ciągu tygodnia, miesiąca czy sprintu
- na naszej liście zadania są wyestymowane lub (w przypadku gdy zespół jest zwolennikiem podejścia #noestimate) odpowiednio zdekomponowane
W tym przypadku możemy w bardzo prosty sposób przełożyć zadania w backlogu na linię czasu:
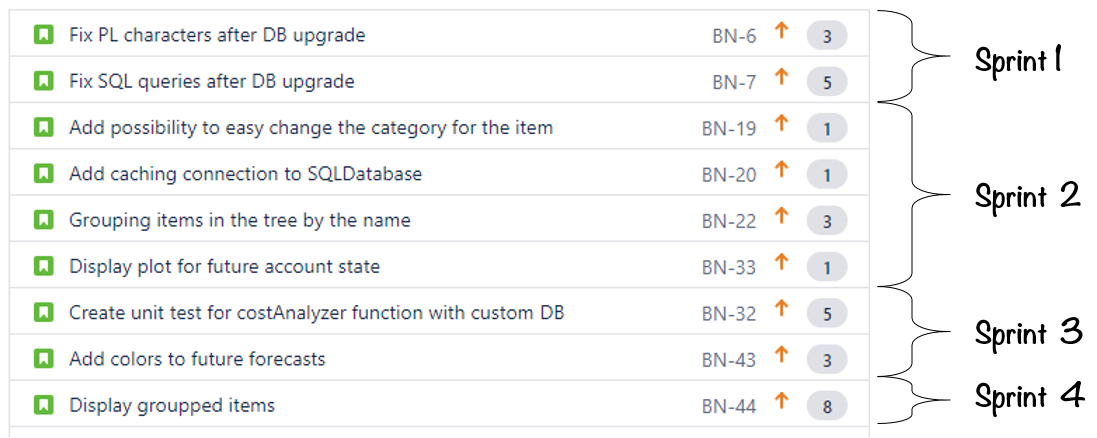
Możemy to robić ręcznie. Ale są też narzędzia, które potrafią robić to automatycznie.
Co więcej, za każdym razem kiedy zmienimy naszą listę zadań – dodamy jakieś zadanie, usuniemy, czy też zmienimy kolejność zadań – to natychmiast dostajemy nową prognozę.
Kiedy pierwszy raz usłyszałem o tej metodzie, byłem pełen sceptycyzmu. „Ej, to jest za proste, żeby mogło działać!”
Myliłem się. Okazuje się, że ten sposób jest jak najbardziej możliwy do stosowania. Pracowałem z zespołami, które z powodzeniem korzystały z tej metody. Zespoły te miały plan dostarczenia na kilka sprintów do przodu i te plany dość dobrze się sprawdzały. Ale jednocześnie okazało się, że…
…jest to bardzo, bardzo trudne
Okazuje się, że zespołów, które z powodzeniem stosują taki sposób planowania, jest mało. Dlaczego jest ich tak mało? Ano dlatego, że szacowanie empiryczne jest trudne.
Jest długa lista przyczyn, które sprawiają, że zespół ma trudności z szacowaniem opartym na swoim doświadczeniu. Brak stabilności zespołu – co chwila ktoś przychodzi i odchodzi. Brak umiejętności dekomponowania zadań. Przerzucenie odpowiedzialności za estymacje i plany na osobę z zewnątrz zespołu. Brak zbierania danych historycznych. Zależności od innych – wiemy, kiedy skończymy swoje zadania, ale nie wiemy ile będziemy czekać na innych. Brak czasu na przyjrzenie się zadaniom, które czekają na wykonanie. Brak czasu na eksperymenty, które dostarczą danych do przewidywania przyszłości.
Tutaj jest ogromne pole do działania dla wszelkiej maści managerów, masterów oraz coachów – ich zadaniem jest budowanie środowiska pracy, które sprzyja estymacji empirycznej.
Jak to można zrobić?
Twórz stabilne zespoły. Zadbaj o kompetencje tego zespołu. Przekaż w ręce zespołu odpowiedzialność za estymacje i za planowanie. Zbieraj dane. Minimalizuj zależności. Dekomponuj zadania. Zadbaj o czas na ciągłe pielęgnowanie listy zadań. Wykonuj eksperymenty, które dostarczą ci wiedzy do estymacji. Zadbaj o inspekcję i adaptację.
Łatwo napisać. Trudno zrobić.
Wszystkie rzeczy są trudne, ale niektóre są trudniejsze
Ktoś mógłby zapytać „Zaraz, zaraz a czym niby różni się przygotowanie takiej listy zadań, wyestymowanie jej elementów od zrobienia starego, dobrego diagramu Gantta z długością trwania zadań i z zależnościami? Przecież to jedno i to samo…”
Rzecz polega na tym, że różnica nie tkwi w technice. Różnica jest w podejściu do szacowania.
Wyobraźmy sobie, że mamy zespół który pracuje nad projektem A i pojawia się nagle konieczność wycenienia projektu B.
Przychodzi do zespołu Manager nr 1 i mówi tak: „Musimy wycenić projekt B, tu jest wszystko, co wiemy o tym projekcie, projekt musi być gotowy na 1 lipca, proszę zdekomponujcie go na zadania, stwórzcie Gantta i powiedzcie kiedy to wszystko będzie gotowe”
Przychodzi do zespołu Manager nr 2 i mówi coś innego: „Musimy wycenić projekt B, tutaj są wszystkie dane, które mamy. Jak możecie oszacować czas wykonania tego projektu na podstawie waszych dotychczasowych doświadczeń? Co utrudnia wam dokonywanie dobrych szacowań? Jak mogę wam pomóc rozwiązać te trudności?”
Widać różnicę? W drugim podejściu mamy przekazanie zespołowi odpowiedzialności za metodę szacowania, akceptację wyniku tego szacowania oraz aktywną chęć pomocy zespołowi w rozwiązywaniu problemów. Z mojego doświadczenia – te właśnie elementy są bardzo rzadko spotykane w wielu organizacjach.
Ujmując rzecz jeszcze trochę inaczej: zamiast szukać magicznej metody estymacji, która ogarnie złożoność naszego systemu, pracujemy nad tym, żeby tą złożoność zmniejszyć.
A jeżeli nie mamy doświadczenia?
Robiliśmy do tej pory założenie, że w przeszłości naszego zespołu mamy jakieś doświadczenia, które możemy wykorzystać. Mieliśmy projekt dostarczenia systemu rekrutacyjnego dla firmy A, mamy do oszacowania projekt podobnego systemu dla firmy B.
A co jeżeli tych doświadczeń nie mamy? Co jeżeli mamy zupełnie świeży zespół i zupełnie nowy problem do rozwiązania? Ci ludzie nigdy nie pracowali wcześniej razem? Nie robiliśmy nic podobnego do projektu, który musimy oszacować?
Gdyby ktoś przyszedł do mnie i zapytał: „Ile zajmie ci zrobienie na szydełku obrusu w kwiatki?” i jeżeli chcę odpowiedzieć na to pytanie uczciwie i odpowiedzialnie, to mam do wyboru dwie opcje.
Pierwsza uczciwa odpowiedź to: „nie mam pojęcia, nigdy w życiu nie miałem w ręku szydełka”. Odpowiedź jest prosta – ale często wymaga dużej odwagi.
I odpowiedź druga: „poczekaj, wezmę szydełko i spróbuję zrobić chusteczkę. Zobaczę ile czasu to mi zajmie i wtedy ci odpowiem”. Czyli wykonujemy jakiś eksperyment, który ma nam dostarczyć wiedzy.
Mówienie, że zrobienie obrusu zajmie trzy miesiące, podczas gdy moja wiedza o szydełkowaniu ogranicza się do tego, że widziałem kiedyś szydełko, jest nieodpowiedzialne. A jeżeli w grę zaczynają wchodzić umowy, zobowiązania i pieniądze – może być źródłem wielu dysfunkcji.
Ale czy to się skaluje?
Mówiliśmy do tej pory o jednym zespole i jednym backlogu. A co jeżeli tych zespołów jest dużo, a produkt który tworzymy jest złożony?
Zasada pozostaje dokładnie taka sama: spróbuj prognozować przyszłość w oparciu o swoje doświadczenia. A jak to implementujemy? To już mocno zależy od sytuacji, w której jesteśmy.
Jeżeli używamy czegoś, co się nazywa „epic” do określania dużych funkcjonalności dostarczanych przez wiele zespołów, to może warto byłoby mierzyć ilość takich epików dostarczanych na miesiąc albo na kwartał? Może warto byłoby zadbać o to, żeby były one porównywalnej wielkości i założyć, że w kolejnym miesiącu dostarczymy ich tyle samo co w poprzednim?
Jeżeli mamy system, który jest wdrażany w wielu krajach i jeżeli w ciągu roku wdrożyliśmy go w trzech krajach – to może warto było założyć, że w następnym roku również wdrożymy go w kolejnych trzech?
Podsumowując
W metodach szacowania opartych na racjonalnych modelach kryje się wiele pułapek – czyhają na nas błędy poznawcze, mamy niepełne informacje i mamy masę niewiadomych… Stosowanie metod empirycznych pozwala nam na weryfikację teoretycznych założeń i pokazuje nam – często boleśnie! – gdzie tak naprawdę jesteśmy.
I to jest dobra wiadomość.
Złą wiadomością jest to, że często przy wytwarzaniu oprogramowania chcemy oszacować czas przejazdu ciężarówką z Moskwy do Pekinu, podczas gdy naszym jedynym doświadczeniem jest przejechanie hulajnogą z Gdańska do Sopotu.
Świetny wpis, dokładnie pokrywa się z moimi doświadczeniami. Szkoda że osoby które przychodzą z wymaganiami i oczekują estymat raczej nie czytają takich wpisów.. choć wciąż mam nadzieję że się w tym mylę;)
A metoda szacowania LWPZD? Liczby wyciągnięte prosto z d…. ;)