 Dziś odbiegając od poprzednich wpisów dotyczących sfery zarządzania w obszarze IT, zajmiemy się bardzo konkretnym problemem, na który można trafić podczas pracy z relacyjnymi bazami danych.
Dziś odbiegając od poprzednich wpisów dotyczących sfery zarządzania w obszarze IT, zajmiemy się bardzo konkretnym problemem, na który można trafić podczas pracy z relacyjnymi bazami danych.
Podczas implementacji raportów jednym z często spotykanych typów raportu, z którymi przyjdzie nam praocować jest szereg czasowy. Upraszczając chodzi o takie zestawienia, w których obserwujemy zdarzenia w dobrze określonych odstępach czasu. Niestety zazwyczaj dane jakimi dysponujemy rejestrują tylko czas wystąpienia zdarzenia, w którym cokolwiek zaobserwowano.
Problem
Dla przykładu rozpatrzmy poniższe zestawienie sprzedaży sztuk towaru określonej kategorii (tabela faktów):
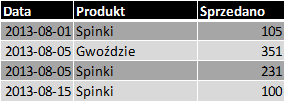
Tabela 1. SPRZEDAZ
Wyobraźmy sobie, że naszego klienta interesuje raport, który będzie pokazywał podsumowanie sprzedaży w PLN za okres od 2013-08-01 do 2013-08-15. Poniżej przedstawiono tabelę z cenami (tabela słownikowa):
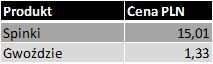
Tabela 2. PRODUKT_CENA
Odpowiednie złączenie wraz z agregacją prowadzi do tabeli pośredniej (tabela agregacyjna):
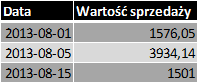
Tabela 3. SPRZEDAZ_WARTOSC
W PL/SQL zapytanie dla tabeli pośredniej będzie wyglądało następująco:
select trunc(sprzedaz.data), sum(produkt_cena.cena*sprzedaz.sprzedano) from sprzedaz,produkt_cena where sprzedaz.produkt = produkt_cena.produkt group by trunc(sprzedaz.data)
Wszystko byłoby dobrze, gdyby nie fakt, że nie posiadamy pełnego zakresu dat. Możliwym podejsciem jest dodatkowe złączenie zewnętrzne tabeli pośredniej z tabelą zawierającą interesujący zakres dat. Skąd w takim razie wziąć brakujące daty?
Rozwiązanie
Daty trzeba sobie wygenerować. W Oracle możemy posłużyć się zapytaniem hierarchicznymi (CONNECT BY PRIOR). Składnia takiego zapytania wygląda następująco:
WITH daty AS ( SELECT level-1 lvl FROM dual CONNECT BY level <= ceil ( ( to_date(:2,'dd-mm-yyyy')+1-to_date(:1,'dd-mm-yyyy') ) ) ) SELECT to_date(:1,'dd-mm-yyyy')+lvl AS data FROM daty WHERE to_date(:1,'dd-mm-yyyy')+lvl < to_date(:2,'dd-mm-yyyy')
, gdzie :1 i :2 to zmienne wiązane będące parametrem
Ostatecznie zapytanie w PL/SQL zwracające interesujące nas wyniki będzie miało postać:
SELECT daty.data AS data, DECODE(wartosc, null, 0, wartosc) AS wartosc
FROM
(
SELECT TRUNC(sprzedaz.data) data
, SUM(produkt_cena.cena*sprzedaz.sprzedano) wartosc
FROM sprzedaz,produkt_cena
WHERE sprzedaz.produkt = produkt_cena.produkt
GROUP BY trunc(sprzedaz.data)
) sprzedaz_wartosc,
(
WITH daty AS
(
SELECT
level-1 lvl
FROM dual CONNECT BY level <= ceil
(
(to_date('2013-08-15','yyyy-mm-dd')+1-to_date('2013-08-01','yyyy-mm-dd'))
)
)
SELECT
to_date('2013-08-01','yyyy-mm-dd')+lvl AS data
FROM daty
WHERE to_date('2013-08-01','yyyy-mm-dd')+lvl <= to_date('2013-08-15','yyyy-mm-dd')
) daty
WHERE daty.data = sprzedaz_wartosc.data (+)
ORDER BY daty.data ASC
Generowanie listy dat w T-SQL (MS-SQL) wygląda również dosyć elegancko:
DECLARE @DataOd DATETIME DECLARE @DataDo DATETIME SET @DataOd = '2013-08-01' SET @DataDo = '2013-08-15'; WITH daty(Date) AS ( SELECT @DataOd as Data UNION ALL SELECT DATEADD(d,1,[Date]) FROM daty WHERE DATE < @DataDo ) SELECT Data FROM daty
Poniżej linki z propozycjami rozwiązania problemu generowania zakresu dat w MySQL oraz PosgreSQL.
PosgreSQL:
W PostgreSQL by uzyskać podobny efekt używa się funkcji generate_series, która pozwala ustalić interesujący nas interwał.
SELECT to_date('2013-08-01','YYYY-MM-DD')+ s.a AS data
FROM generate_series(0,to_date('2013-08-15','YYYY-MM-DD')-to_date('2013-08-01','YYYY-MM-DD'),1) as s(a);
MySQL:
http://stackoverflow.com/questions/510012/get-a-list-of-dates-between-two-dates
Podsumowanie
Powyżej udało się przedstawić proste rozwiązanie bardzo często spotykanego problemu braku istnienia obserwacji, który ujawnia się przy budowaniu raportów opartych o szereg czasowy dla chyba najbardziej popularnych silników relacyjnych baz danych. Zaskoczeniem jest bardzo prosty sposób generowania wszelkich zakresów w PostgreSQL. Rozwiązania dla wielkich komercyjnych baz danych wyglądają dosyć elegancko i są proste, niemniej jednak nadal pozostawiają pewne braki. Czy można łatwo zamknąć zapytanie w widoku, tak by nie istniała konieczność jego modyfikacji? Czy istnieje homogeniczne rozwiązanie spójne dla dowolnej relacyjnej bazy danych wspierającej standardy, w końcu język SQL jest standardem… podobno ;-)
Warto zauważyć, że takie rozwiązanie bardzo obciąża bazę i prowadzi do tworzenia dużych kolekcji w pamięci. Sprzedajemy przecież nie tylko gwoździe i szpilki ale także śruby, nakrętki, … To „normalny” problem z iloczynem kartezjańskim zbiorów.
Z n wierszy wejściowych generujemy do n*<okres analizy> wierszy w pamięci.
Zamiast obciążać serwer generując z małej ilości danych wejściowych dużą kolekcję wyjściową… można obejść logikę naokoło, wygenerować minimum danych na serwerze, ściągnąć je do maszyny klienta (rozmiar danych jest mały więc zadziała to szybko i nie obciąży sieci) i już w aplikacji klienckiej wygenerować pożądane wyniki.
Wydaje mi sie, że to co warto użyć zależy od konkretnego problemu i sposobu użycia bazy danych.
Jeżeli mamy do czynienia z systemem raportowym typu OLAP generującym raporty w określonych cyklach, a nie mamy do czynienia z aplikacją instalowaną u klienta typu OLTP, to może nie warto przenosić logiki z silnika bazy danych do części klienckiej, a obciążenie bazy też nie będzie problemem, bo zapytań do silnika raportowego i klientów jest mniej niż przy systemie transakcyjnym.