W 2012 roku Henrik Kniberg opublikował krótki film, w którym wyjaśnia ideę „Agile Product Ownership in a Nutshell”. Filmik zdecydowanie warto obejrzeć – a ja dzisiaj chciałbym wykorzystać obrazek z tego filmu do zastanawienia się, dlaczego dużym organizacjom IT trudno jest zwinnie rozwijać produkty.
Naszkicowany przez Kniberga obraz zwinnego wytwarzania produktu wygląda tak:
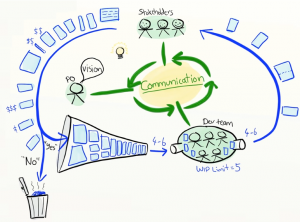
Mamy tutaj trzy kluczowe przepływy:
- Przepływ pomysłów na zmiany (lewa niebieska strzałka) – interesariusze (Stakeholders) definiują funkcjonalności, Właściciel Produktu priorytetyzuje je i umieszcza w kolejce do wykonania,
- Przepływ zmian w aplikacji (prawa niebieska strzałka) – zespół deweloperski często dostarcza system z nowymi funkcjonalnościami do interesariuszy,
- Przepływ informacji (zielone strzałki pośrodku) – interesariusze, zespół deweloperski oraz Właściciel Produktu komunikują się ze sobą.
Sensem zwinności nie są sprinty, planowania i backlog-i. Chodzi o to, żeby zapewnić te powyższe przepływy: szybki przepływ idei, szybką priorytetyzację tych idei, częste dostarczanie systemu oraz sprawną komunikację. Chodzi o to, że w przypadku pojawienia się pomysłu na funkcjonalność aplikacji, która przyniesie nam milion mieszków złota – możemy bardzo szybko ten pomysł omówić, wycenić, spiorytetyzować, zaimplementować i wdrożyć na środowisko produkcyjne. Ta-dam!
Kiedy małe firmy zaczęły stosować ten sposób działania, okazało się, że przynosi on znacznie lepsze rezultaty niż praca w trybie realizacji długoterminowych projektów. Stąd wzięła się „moda na agile”, która dotarła również do dużych organizacji. Ale próbując zastosować ten sposób działania w dużej organizacji IT, która pracuje nad rozwojem dużego systemu, natychmiast napotykamy na…
Ogromne problemy przy skalowaniu
Przedstawiając ideę zwinnego wytwarzania produktu ludziom pracującym w dużych firmach możemy usłyszeć: „ale to nie zadziała u nas”, „my jesteśmy inni”, „to działa tylko w małej skali”.
Spróbujmy więc zaznaczyć na rysunku te elementy zwinnego świata, które są trudne dla rozwoju dużych systemów oraz dużych dla organiacji:
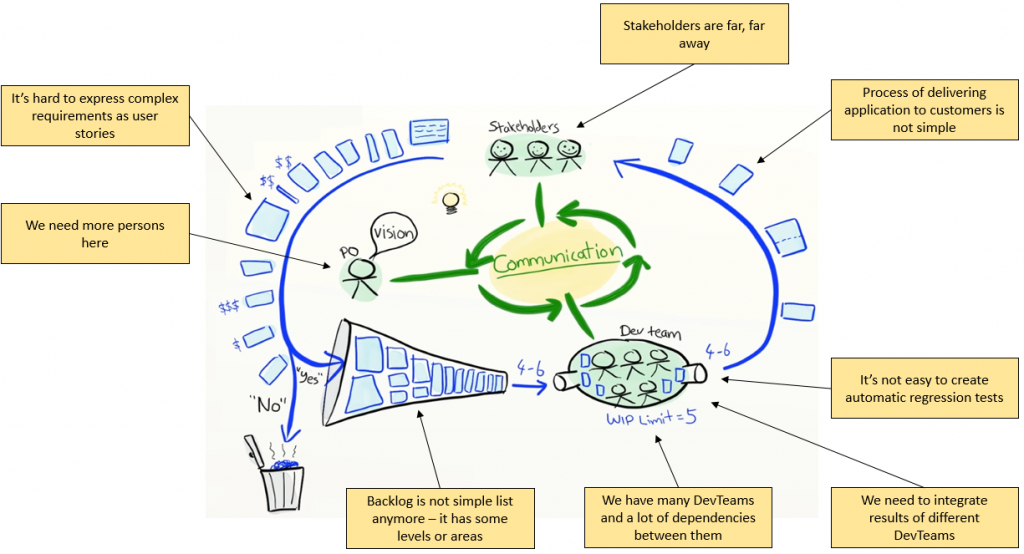
Rozpoczynając od samej góry. Zwykle w takim projekcie interesariusze lub użytkownicy systemu są bardzo oddaleni od zespołów deweloperskich. Nie możemy wprowadzić żadnej zmiany w systemie bez zleceń „podpisanych w trzech egzemplarzach, wysłanych, odesłanych, zakwestionowanych, zgubionych, odnalezionych, przedstawionych opinii publicznej, znów zgubionych, porzuconych ostatecznie na trzy miesiące na kupie kompostu i zużytych jako surowiec wtórny do rozpalania ognia”.
Wymagania. Jeżeli projektujemy internetowy system wymiany książek, łatwo jest zapisać wymagania jako historyjki użytkownika. Ale w dużym systemie wymagania mogą być bardzo złożone. Może być tak, że jakiś zespół deweloperski przez rok pracuje nad interfejsem do eksportu danych – mamy jedną historię („jako użytkownik systemu chciałbym wyeksportować dane ubezpieczeń klientów”) i przez długi, długi czas rozgryzamy, skąd wziąć te dane, w jaki sposób je przetworzyć i w jaki sposób je wyeksportować.
Często jest tak, że nie mamy w organizacji jednej osoby, która może pełnić rolę Właściciela Produktu – obszar do priorytetyzacji jest po prostu za duży. Musimy więc podzielić Backlog Produktu na obszary i w jakiś sposób określić zależności między tymi obszarami oraz ich właścicielami. Często również Backlog przestaje być listą i wprowadzamy w nim jakąś hierarchię w stylu: Theme / Epic / Story / Task. Utrzymanie tego Backlogu zaczyna być pracochłonne.
Wiele zespołów deweloperskich oznacza wiele problemów. Przede wszystkim pojawia się problem z tym, co opisuje Scrum Guide w zdaniu „Development Teams are cross-functional, with all of the skills as a team necessary to create a product Increment”. W dużych organizacjach często pojawia się specjalizacja, silosy kompetencyjne oraz masa zależności. Żeby wprowadzić zmianę w systemie potrzeba jest kooperacja wielu zespołów. A dodatkowo często zespoły te są rozproszone.
Wiele zespołów to również konieczność integracji ich pracy. Problemy przy integracji systemów są normą – zawsze trafia się coś, czego nie przewidzieliśmy. Nie znam programisty, który by nie doświadczył historii „działa, działa, działa, integrujemy, OMG!”.
Żeby zachować stabilne tempo rozwoju systemu, musimy tworzyć testy regresji. Dodając do systemu nowe funkcjonalności nie chcemy za każdym razem pracochłonnie sprawdzać, czy wszystkie poprzednie funkcje działają poprawnie. Tymczasem w dużych systemach IT najczęściej albo nie mamy testów regresji, albo wykorzystujemy plaftormę technologiczną na której pisanie testów regresji jest trudne, albo mamy coś, co tylko udaje testy regresji (gorąco polecam artykuł opisujący „teatrzyk CI”).
I na koniec mamy wydanie systemu. Duże organizacje mają wiele ważnych powodów, którymi tłumaczą wydawanie systemów w dużych odstępach czasowych: nasz system musi przejść kosztowne testy end-to-end; nasz system musi być certyfikowany przed wydaniem; nasz system jest zintegrowany i klienci muszą dopasować się do naszych zmian; nasz system jest instalowany lokalnie u klientów i nowe wydanie oznacza duży koszt. W rezultacie wdrożenie nowej wersji systemu jest wykonywane raz na rok albo raz na kwartał – nie jesteśmy z tego powodu szczęśliwi, ale już się do tego przyzwyczailiśmy i jakoś z tym żyjemy.
Ale to jeszcze nie wszystko…
Mamy jeszcze kilka dodatkowych problemów, które często pojawiają się w dużych organizacjach – nie są one bezpośrednio związane z naszym rysunkiem, ale mają na niego duży wpływ.
Pierwszym czynnikiem może być nastawienie członków zespołów. Tworzenie obszarów funkcjonalnych i silosów kompetencyjnych bardzo często skutkuje nastawieniem na realizację celów właśnego zespołu. Żeby osiągnąć sukces w zespole Scrum trzeba zmienić swoje podejście z „czekam na przydzielenie mi zadania do realizacji” na „aktywnie szukam sposobu żeby wspólnie ze zespołem zrealizować cel sprintu”. Trzeba zmienić nastawienie „w analizie, którą dostałem, znowu jest pełno dziur” na „usiądźmy z analitykiem i spróbujmy zrobić razem lepszą analizę”. Trzeba zmienić „napisałem swoją część i ona działa – a jak całość nie działa, to problem jest po drugiej stronie”.
Nasza organizacja może być przyzwyczajona do pracy w trybie projektowym – tj. przyzwyczajona do rozbijania pracy na projekty z jasno określonym celem, zakresem oraz budżetem. Trudno jest wtedy mówić o rozwoju produktu. Trudno wtedy również przekazać władzę nad rozwojem produktu z rąk menedżerów projektów w ręce właścicieli.
Nasza organizacja może być przyzwyczajona do pracy, w której wie (lub wydaje jej się, że wie!), co trzeba dostarczyć – więc nie widzimy sensu w reprioretyzacji wymagań. Skoro dobrze wiemy, co trzeba zrobić – dlaczego mamy tworzyć mechanizmy ułatwiające zmiany w tych wymaganiach?
Może występować również brak zaufania między dostawcą oprogramowania a klientem – zwłaszcza w przypadku, kiedy pracujemy w oparciu o kontrakt, który z góry określa zakres i koszt prac. Trudno mówić o zaangażowaniu i dobrej współpracy w przypadku, w którym klient traktuje dostawcę IT jak dostawcę pizzy – dostawca ma zrobić co trzeba, bo za to mu płacimy.
I ostatnim elementem, na którym chciałbym zwrócić uwagę, są menedżerzy w organizacji. Po pierwsze mogą oni być skupieni na realizacji celów własnego zespołu, departamentu czy sekcji. Dyrektor do spraw finansowych będzie skupiony na tym, żeby nie przekroczyć planu finansowego. Kierownik działu testów będzie miał do spełniania SLA dotyczące czasu rozwiązywania błędów. Bardzo łatwo jest zgubić sens pracy organizacji w gąszczu lokalnych optymalizacji.
Menedżerzy mogą również czuć się zagrożeni wprowadzaniem metod zwinnych utożsamiając je z zagrożeniem swojego miejsca pracy lub z zagrożeniem funkcji, które są realizowane przez ich zespół.
Water-Scrum-fall nie jest rozwiązaniem!
Często efekt próby wprowadzania zwinności przy wszystkich opisanych ograniczeniach kończy się takim efektem (tym razem autorem obrazka jest Jez Humble):
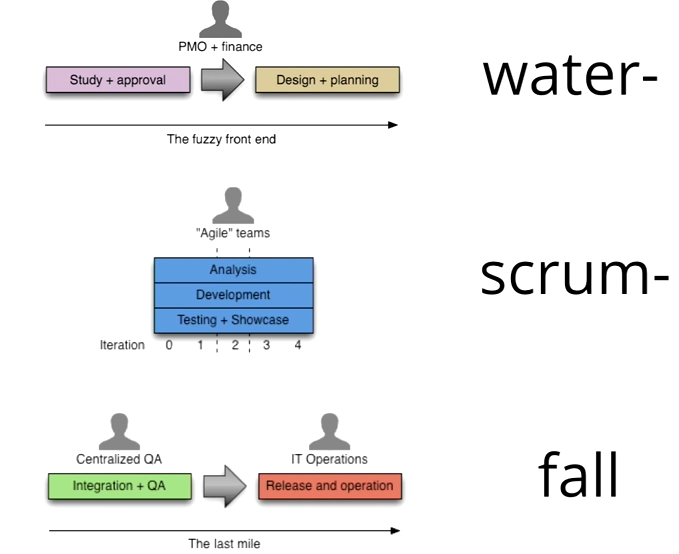
Zespoły pracują w sprintach – ale zanim zabiorą się do pracy przechodzimy przez długi i kosztowny proces planowania inicjatyw. A po zakończeniu pracy zespołu deweloperskiego czeka nas bolesny proces integracji i wdrożenia zmian. Małe kółko sprintowe, które obraca się raz na dwa tygodnie, wpisane jest w wielke koło projektowo-wdrożeniowe obracające się raz na pół roku. Nawet jeżeli zespół jest w stanie szybko zaimplementować jakąś zmianę – to i tak od momentu wymyślenia zmiany do momentu jej wdrożenia na środowisko produkcyjne mijają długie, długie miesiące…
Szukamy rozwiązania we framework’ach
Jeżeli mamy jakiś problem, to często szukamy podpowiedzi w jakiś framework’ach. Mamy ich trochę do wyboru – jest Scaled Agile Framework, LeSS, Nexus… I faktycznie, znajdziemy tam pewne podpowiedzi.
Zarówno SAFe, jak i LeSS podpowiedzą nam, jak można skalować backlog. Wszystkie frameworki mówią o konieczności redukcji zależności pomiędzy zespołami. Wszystkie mówią o budowaniu „feature teams”. Nexus podkreśla ważność ciągłej integracji.
Ale w żadnym framework’u nie znajdziemy gotowego przepisu, które powie nam jak zbliżyć zespoły deweloperskie do klienta. Nie znajdziemy gotowej metody tworzenia testy regresji w dużych systemach. Nie znajdziemy porad, jak radzić sobie z różnymi wyzwaniami dotyczącymi release’ów. Nie znajdziemy ich z bardzo prostego powodu – problemy dużych organizacji są tak różne, że nie ma jednej, wspólnej recepty na sukces…
Dlatego we framework’ach nie znajdziemy zbyt wielu gotowych rozwiązań. Ken Schwaber, współtwórca Nexusa, mówi tak: „Scaled Professional Scrum is not a solution. It is a framework, within which you can think and apply principles to scale Scrum and to be as productive as possible”.
Rozpędzamy koło zamachowe…
Wróćmy jeszcze raz do naszego pierwszego obrazka:
Idea zwinnego wytwarzania oprogramowania jest prosta: pomysł na zmianę, który wychodzi od interesariuszy, może bardzo szybko wrócić do nich w formie gotowej zmiany w aplikacji. Przypomina to koło zamachowe, która obraca się raz na kilka-kilkanaście dni i za każdym obrotem przynosi coraz to nowe zmiany w działającej aplikacji.
Wszystkie opisane wyżej problemy powodują, że w dużych organizacjach to koło obraca się niezmiernie powoli.
W bólach i trudach osiągamy jeden obrót na kwartał, pół roku, rok… W konsekwencji trudno jest docenić zalety zwinnego podejścia. Jeżeli rezultaty priorytetyzacji backlogu widzimy dopiero po kilku miesiącach – to trudno jest zobaczyć powody, dla których warto ten backlog pielęgnować.
Wdrażanie zwinności w dużych organizacjach przypomina żmudne oliwienie tego koła, aby mogło obracać się coraz szybciej. Jest to trudne, ponieważ każda z wymienionych wyżej trudności jest potencjalnym hamulcem. Jest to trudne również dlatego, że dopóki nasze koło nie nabierze prędkości, nie widać korzyści z naszych wysiłków.
Dopiero kiedy nasze koło zaczyna się obracać coraz szybciej i szybciej, dopiero kiedy zaczynamy widzieć, że dostarczamy zmiany w coraz krótszych interwałach czasowych – zaczynamy dostrzegać prawdziwe korzyści wynikające ze zwinnego tworzenia oprogramowania.
A co w Twojej organizacji najbardziej spowalnia koło dostarczania zmian?
Życie tak wygląda.
Detale są pomijane na początku.
Na końcu są najważniejsze detale.
Brawo.
W wielu firmach właśnie takiego koła brak. A jeśli już jest, to taka 'ósemka’, że trudno to naprawić.
Bardzo fajny artykuł. Miło się czyta. Chętnie podzielę się swoimi doświadczeniami i punktem widzenia. U mnie w organizacji skalujemy agile posiłkując się SAFe (Scaled Agile Framework), ale podejrzewam, że wiele zagadnień może podobnie funkcjonować niezależnie od tego, czy inspirujemy się SAFe’m, LESS’em, czy innym podejściem.
Poniżej moje komentarze do wybranych akapitów z cytowanymi początkami tychże.
“Rozpoczynając od samej góry. Zwykle w takim projekcie interesariusze lub użytkownicy systemu są bardzo oddaleni od zespołów deweloperskich….”
Prawda. Bolesna. Zwłaszcza w przypadku pracy dla klienta zewnętrznego. Dużo wtedy zależy od kultury pracy zamawiającego i postawy tych, którzy pełnią rolę proxy między zespołem wykonawcy a biznesem zleceniodawcy. Zdarza się, że Product Ownerzy współpracują bezpośrednio z zespołami, zdarza się też że fajnie potrafi sobie poradzić kierownik projektu, albo że nieźle dogadują się kierownicy projektów po obu stronach… no, ale zaraz pojawią się głosy “co to za agile z Project Managerem?”. Dużo lepiej może wyglądać sytuacja w projektach i programach wewnętrznych, choć bywa też zupełnie na odwrót, klient wewnętrzny potrafi być cięższy. Forma rozliczeń zazwyczaj sprawia, że w wewnętrznych projektach jest łatwiej, ale oprócz rodzaju kontraktowania ogromną rolę odgrywa kultura organizacyjna i w tym obszarze metodyki mogą pomóc podpowiadając w obszarze narzędzi, ról i procesów.
“Wymagania. Jeżeli projektujemy internetowy system wymiany książek, łatwo jest zapisać wymagania jako historyjki użytkownika. Ale w dużym systemie wymagania mogą być bardzo złożone….”
Wszystko, to bardzo cenne spostrzeżenia. Prosto z życia i na bank wielu z nas to dotknęło. Cała sztuka w skalowaniu polega na tym, żeby skalować w dużo szerszym kontekście niż narzędzia, procesy i role deweloperskie. Da się sensownie wyskalować rolę Product Ownera (u mnie w organizacji mamy następującą hierarchię: Solution Manager – Product Manager’owie – Feature Ownerzy, każdy zajmuje się dedykowanym poziomem rozwoju produktu, od wizji po buttony, co zastępuje “uniwersalnych” Product Ownerów którzy mają bardzo szeroki zakres odpowiedzialności, ale często zbyt małe przełożenia w poszczególnych obszarach objętych projektem). Nie rozpiszę się tutaj na temat zakresu obowiązków poszczególnych ról, ale wyskalowanie podstawowych ról takich, jak deweloper, Scrum Master i Product Owner od poziomu zespołu, poprzez poziom programu aż do portfela, jest możliwe i mocno pomaga w organizacji wielu zespołów i wielu poziomów wymagań.
“Wiele zespołów to również konieczność integracji ich pracy. Problemy przy integracji systemów są normą – zawsze trafia się coś, czego nie przewidzieliśmy…..
I na koniec mamy wydanie systemu. Duże organizacje mają wiele ważnych powodów, którymi tłumaczą wydawanie systemów w dużych odstępach czasowych: nasz system musi przejść kosztowne testy end-to-end; nasz system musi być certyfikowany przed wydaniem; nasz system jest zintegrowany i klienci muszą dopasować się do naszych zmian; nasz system jest instalowany lokalnie u klientów i nowe wydanie oznacza duży koszt…. “
Z tym jest rzeź. U mnie w Pociągu (Agile Release Train) przetwarzamy około 9000 elementów backlogu na kwartał, a nie jest to wielkie rozwiązanie. Za PBI’ami idą w parze zależności, a za nimi potrzeba synchronizacji i integracji. Niektóre frameworki wydzielają do testów systemowych i integracji osobne, dedykowane zespoły (tak też my robimy) ale dalej pozostaje cała masa działań do skoordynowania po stronie samych zespołów i większości sukces zależy od tego, jak mocno wezmą do siebie zasadę Built-in quality. Nieco pomaga ograniczanie WIP i zakresów przyrostów, integracja całego rozwiązania co sprint, dema dem i inne, można takie mechanizmy samemu wypracować, niektóre są dość oczywiste, ale warto też zainspirować się dobrymi praktykami, które podpowiadają frameworki.
“Szukamy rozwiązania we framework’ach
Jeżeli mamy jakiś problem, to często szukamy podpowiedzi w jakiś framework’ach. Mamy ich trochę do wyboru – jest Scaled Agile Framework, LeSS, Nexus… I faktycznie, znajdziemy tam pewne podpowiedzi.”
Taka to już specyfika skalowania, że dotyka tak dużych obszarów organizacji, że dużo ciężej to ogarnąć frameworkiem niż pracę zespołu lub paru zespołów. Im bliżej znajdujemy się poziomu portfela i zarządzania strategicznego, tym frameworki coraz bardziej stanowią li tylko inspirację. Propozycje ról, narzędzi, procesów są wtedy cenne, bo nie warto za każdym razem wymyślać koła na nowo i jeśli jest możliwość skorzystania z czyichś doświadczeń, to powinniśmy ją rozważyć. To co mnie osobiście przekonało do SAFe’a, to dużo cennych sugestii i wytycznych odnoszących się do tego, co kształtuje kulturę organizacyjną i stanowi uzupełnienie do narzędzi. Rozpisanie ról, artefaktów, rytuałów to tylko część konstruowania systemu, druga część to sposób, w jaki będziemy ich używać, to co mamy z tyłu głowy. SAFe nazywa to Lean-agile mindset i opisuje to za pomocą 9 pryncypiów. To one mówią między innymi o tym jak dużą rolę w sukcesie skalowania zwinności odgrywa decentralizacja podejmowania decyzji, motywowanie pracowników, czy ograniczanie zakresów przyrostów. I to jest właśnie moim zdaniem to, co robi największą różnicę i decyduje o sukcesie skalowania. To jaką kulturę zaszczepimy i rozpropagujemy w organizacji. Narzędzia i procesy, to detale, potrzebne, ale w skali całej organizacji to jednak pikuś. Dużo ważniejsze jest zrozumienie idei zwinności i jej wpływu na poszczególne obszary firmy oraz motywacja całej organizacji do bycia zwinnym. Jeśli jest poparcie dla agile’a wynikające ze zrozumienia jego przesłania i mechanizmów, to i rozwiązania się znajdą.
Jeśli zatem miałbym wskazać największy spowalniacz koła dostarczania zmian w organizacjach, w których pracowałem do tej pory, to było nim utrzymywanie stanu, w którym agilem interesowała się na poważnie jedynie garstka interesariuszy, często ograniczająca się do zespołów deweloperskich, PMów i Product Ownerów. Reszta żyła w innej czasoprzestrzeni. Nie da się skalować mechanizmów, jeśli nie ma do tego przygotowanego odpowiedniego gruntu.
Dziękuję za te komentarze i przemyślenia!
Zdecydowanie zgadzam się z Twoim podsumowaniem. Widziałem już sytuacje, w której organizacja zatrudniała pracowników lub konsultantów do zbudowania zwinnych narzędzi i procesów – ale po rozpoczęciu pracy okazywało się, że „brakuje gruntu”, brakuje zrozumienia, po co w ogóle wykonujemy taką zmianę.
Czy można zatem to podsumować, że w dużych (ogromnych) projektach nie wystarczy wprowadzić Scruma, żeby wszystko zaczęło dobrze funkcjonować, a trzeba zastanowić się jak firma działa, jaką projekt ma specyfikę, jacy to ludzie, gdzie obecnie są problemy, wypaczenia i patologie i jakie mechanizmy się tu sprawdzą, a jakie nie, inspirując się sprawdzonymi praktykami zarządzania projektami, IT, organizacjami, żeby dobrać jak najlepsze rozwiązania i nastawić się jeszcze na ich optymalizację?
Można tak podsumować :-)
Scrum jest świetnym fundamentem do budowania zwinnej organizacji – ale jeżeli ograniczymy się do wprowadzenia 3 ról, 5 zdarzeń i 3 artefaktów, jeżeli zabranie nam „Whole Product Focus”, to jest duża szansa na to, że niewiele się zmieni na lepsze.
Jedyną wątpliwość budzi u mnie stwierdzenie „sprawdzone praktyki zarządzania projektami IT”.
Wprowadzenie zwinności bardzo często oznacza przejście z zarządzania projektami na zarządzanie produktami. Ale to kolejny duży temat…
Faktycznie, coś jest na rzeczy z tym przechodzeniem z zarządzania projektami na zarządzanie produktami. Np. SAFe odchodzi od określenia „projekt” skupia się na strumieniach wartości, które dostarczają rozwiązania i rozbudowują je iteracyjnie. Eh, duży skrót myślowy, jeśli się interesujecie tym tematem, to więcej znajdziecie w tym artykule:
http://atscale.pl/agile-waterfall-do-gory-nogami/
i w paru innych na moim blogu.
Tak w skrócie. Bardzo duży nacisk kładziony jest na płynność pracy i stałość zespołów. Dąży się do tego, żeby nie było zrywów projektowych w stylu start-zasuwamy-stop i czekamy na nowy projektem (albo bierzemy udział w 5 projektach w każdym na 20%, albo 25% ;] znam też takie przypadki), ich miejsce zajmuje stały rytm prac, stabilnych, dedykowanych zespołów:
jakiś pomysł biznesu dojrzewa, trafia na planowanie przyrostu programu, jest dewelopowany, wdrażany na kolejne środowiska i w na żądanie biznesu, w odpowiednim biznesowo momencie wdrażany na produkcję, a w kolejce czekają kolejne funkcjonalności do dostarczenia. Nie jest tak bardzo istotne posiadanie precyzyjnego planu wdrożeń i rozwoju na lata z góry, tylko zdolność planowania z wyprzedzeniem mniej więcej kwartalnym i sprawnego dostarczania tych wartości, które są danemu projektowi w danym momencie najbardziej potrzebne, by konkurować z sukcesem.
Oczywiście nie do każdego przedsięwzięcia takie podejście pasuje, potrafię sobie wyobrazić całą masę projektów, których nie da się sensownie zrobić inaczej niż waterfallem, ale wiele firm zmierza w tą stronę.
Nie mniej jednak, czy nazywamy to podejściem projektowym czy produktowym, to ten obszar wiedzy chyba jeszcze długo będziemy nazywali zarządzaniem projektami.